找到
11
篇与
技术教程
相关的结果
- 第 2 页
-
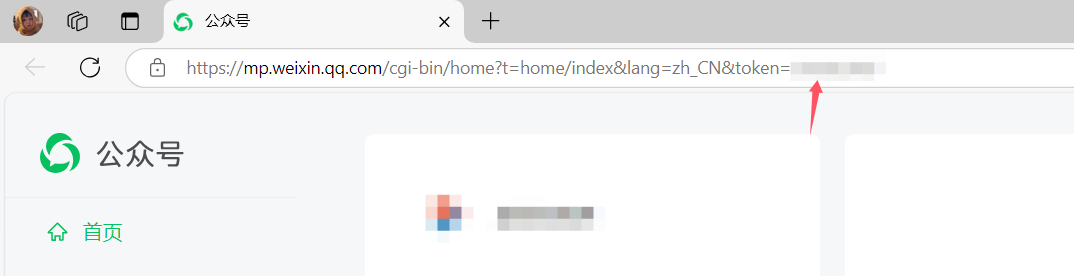
 网盘变现助手公众号配置教程+购买授权 隐藏内容,请前往内页查看详情 网盘变现助手 ①支持群聊、私聊自助搜索网盘资源 ②支持单群聊授权,可进行出租机器人 ③百分之99以上的回复内容自定义 ④每日更新资源群聊推送,用户不容错过最新资源 ⑤超强大的微信公众号自动化发布体系,支持多模版发布,资源AI生成文章内容,无视实名群发文章等 公众号配置(新版本此项废除) 打开微信公众平台:https://mp.weixin.qq.com/ 并扫码登录 登录后查看网址栏,复制地址栏中的token填入插件后台 图片 键盘按F12打开浏览器开发者工具,按下图顺序所示,复制Cookies项的全部内容填入插件后台 图片 最后插件后台点击保存全部 模版代码抓取 左上角点击 内容管理 -> 草稿箱 图片 鼠标悬浮移到 新的创作 字样上,点击写新图文 图片 按你自己的意愿创作好看的模版,键盘按F12打开浏览器开发者工具,按下图顺序所示,找到content0项并复制所有内容 关键词:"operate_appmsg" 图片 新建一个空txt文件打开,把刚才复制的内容粘贴,左上角点击 文件 -> 另存为,文件名随意填写,文件后缀填写 .xml,编码选择 ANSI 图片 把文件保存到框架插件文件夹的文章模版文件夹里即可 图片 AI生文配置 打开"华为云"官网,注册并登录。 点击官网首页的ModelArts Studio大模型即服务平台,进入控制台 图片 按下图点击 模型推理 -> 旧版服务 图片 然后随便开通一个模型,点击后面的调用说明,获取调用API、模型名称填入插件后台 图片 图片 在 步骤一: 获取API Key 前往 API Key管理 创建新的API后,填入后台即可。 图片
网盘变现助手公众号配置教程+购买授权 隐藏内容,请前往内页查看详情 网盘变现助手 ①支持群聊、私聊自助搜索网盘资源 ②支持单群聊授权,可进行出租机器人 ③百分之99以上的回复内容自定义 ④每日更新资源群聊推送,用户不容错过最新资源 ⑤超强大的微信公众号自动化发布体系,支持多模版发布,资源AI生成文章内容,无视实名群发文章等 公众号配置(新版本此项废除) 打开微信公众平台:https://mp.weixin.qq.com/ 并扫码登录 登录后查看网址栏,复制地址栏中的token填入插件后台 图片 键盘按F12打开浏览器开发者工具,按下图顺序所示,复制Cookies项的全部内容填入插件后台 图片 最后插件后台点击保存全部 模版代码抓取 左上角点击 内容管理 -> 草稿箱 图片 鼠标悬浮移到 新的创作 字样上,点击写新图文 图片 按你自己的意愿创作好看的模版,键盘按F12打开浏览器开发者工具,按下图顺序所示,找到content0项并复制所有内容 关键词:"operate_appmsg" 图片 新建一个空txt文件打开,把刚才复制的内容粘贴,左上角点击 文件 -> 另存为,文件名随意填写,文件后缀填写 .xml,编码选择 ANSI 图片 把文件保存到框架插件文件夹的文章模版文件夹里即可 图片 AI生文配置 打开"华为云"官网,注册并登录。 点击官网首页的ModelArts Studio大模型即服务平台,进入控制台 图片 按下图点击 模型推理 -> 旧版服务 图片 然后随便开通一个模型,点击后面的调用说明,获取调用API、模型名称填入插件后台 图片 图片 在 步骤一: 获取API Key 前往 API Key管理 创建新的API后,填入后台即可。 图片
-
网盘搜索(网盘变现)、短剧搜索程序索引+微信公众号自动发文章+保姆级搭建教程 39.9价格如下: ①短剧搜索源码+美化包 需要自己动手搭建,无技术指导 899价格商品包含内容如下: ①短剧搜索网站+微信机器人搜索+公众号自动发布文章+微信对话平台 ②短剧搜索网站美化包(包含logo制作,背景图制作等) ③帮忙一条龙部署,无需自己动手配置 以上项目持续包更新,需要自备两台服务器。咨询请添加QQ号2786883659 程序介绍 (前往体验) 资源管理系统是一款拥有后台的个人网盘资源管理程序;可以帮你管理、搜索自己的网盘资源; 功能特点 一键转链: 快速将他人分享的链接转换为您个人的专属链接,提升资源管理效率。 网盘支持: 特别支持夸克网盘,助力网盘拉新! 智能搜索: 提供三种搜索模式:精准搜索、模糊搜索和分词搜索,满足不同用户的搜索需求。 资源更新: 系统自动转存每日新增资源,保持资源库的新鲜度。 广告过滤: 自动过滤并删除转存过程中的广告内容,提供更纯净的资源体验。 后台管理: 后台支持配置SEO参数、伪静态网址和网站地图等,优化网站搜索引擎排名。 收益模式: 通过游客搜索转存资源或会员充值,实现网站收益。 程序截图 图片 图片 图片 图片 图片 搭建教程 上传源码 把源码上传到宝塔或支持设置PHP超时限制的服务器/主机里 选择环境PHP7.2并设置超时限制为86400,设置保存后重启PHP7.2服务 图片 上传文件夹内的data.sql到你的数据库里,并配置.env文件填写数据库链接地址 图片 图片 设置网站运行目录public,并设置thinkphp伪静态 location ~* (runtime|application)/{ return 403; } location / { if (!-e $request_filename){ rewrite ^(.*)$ /index.php?s=$1 last; break; } }图片 进入程序后台,后台地址:https://你的域名/qfadmin 账号密码:admin 123456 点击资源,然后点击账号管理,输入你的夸克Cookie 图片 如何获取夸克网盘Cookie? 百度搜索夸克网盘,打开网页版,登录账号后到夸克网盘网页版首页界面,键盘点击F12打开开发者工具,按下图所示复制Cookie到网站的账号管理中 图片 检查自己的网盘是否有足够大的空间存储资源,容量在10T以下,那么空间是不够的,空间不够的先去看这篇文章 -> 夸克网盘空间不足?私人教程教你免费升级60T 图片 已经有足够的空间后,进行下一步,按下图所示找到资源 - 分类管理 - 一键转存 图片 点击一键转存后需要等待0.5天-1天的时间,才可把资源全部同步到你的网站上 如果没有足够的空间又想尽快上线使用的,联系我拿短剧的表格文档,可一键导入 最后,配置宝塔计划任务 添加宝塔计划任务 GET 以下网址(每6小时一次或每日一次),会自动更新每日资源 http://你的网址/api/source/day 图片 常见问题 全部转存执行1分钟~5分钟后中断问题,修改超时限制 该操作用时很长,请设置最大值86400,设置后需重启下服务 非7.2版本导致的报错,请自行解决,不要再问,不会就百度或者老老实实用7.2 访问显示nginx 404 Not Found请设置设置thinkphp伪静态 后台报错请检测数据库文件是否正常配置成功;每日更新报错请检测数据库文件是否正常配置成功、并使用国内服务器或主机,计划任务请不要访问过于频繁,设置每6小时一次即可 网站经常打不开,出现500的情况,未具体找到原因,可能是因为服务器配置太低,分词功能占用内存过高导致的 升级服务器配置或后台修改搜索模式改为“精准搜索” 下载源码(更新地址) 隐藏内容,请前往内页查看详情 更新日志 - 19be6b 19be6b 19be6b 19be6b 19be6b 19be6b 微信对话平台部署 (前往体验) 登录微信对话平台 https://chatbot.weixin.qq.com/login ,创建一个想要的机器人名字。行业类型随意 图片 来到后台点击应用绑定-开放api-申请权限,填写相关信息 图片 获取到api秘钥后对应填写在网站的 app/api/controller/chatbot 文件里面,并填写回调地址:https://你的域名/api/chatbot 图片 图片 在微信官方对话后台点击发布,教程结束! 图片 网页机器人对接部署 (前往教程) 图片 微信机器人部署教程 以下方案如部署启动不成功,请考虑系统环境问题,目前已知宝塔腾讯专享版无法启动项目。 Python部署方案 如不想去Github下载,请划到第四步下载打包好的文件,可省去 第一步 和 第四步 的做法 搭建chatgpt-on-wechat项目,前往项目地址下载 准备一个服务器,此教程以宝塔为例,按下图所示在宝塔新建一个文件夹,并上传刚刚下载的机器人源码到根目录 图片 图片 安装Pythoe环境,版本在 3.7.1~3.9.X 之间,推荐3.8版本,3.10及以上版本在 MacOS 可用,其他系统上不确定能否正常运行,此处使用Python-3.8.19版本 图片 然后把网盘资源管理系统源码的chatgpt-on-wechat文件夹里的文件按照以下路径放入机器人项目文件夹(覆盖原文件) config.json config.py:机器人项目根目录 chat_channel.py:机器人项目根目录/channel/chat_channel.py 嫌麻烦的直接下载打包好的文件 短剧微信机器人 下载地址:https://pan.quark.cn/s/5ab8763726d5 提取码: 打开config.json文件,修改duanju_url字段为你的网盘资源管理系统的网址,测试群聊改成你群聊名称保存,一行授权一个群聊 图片 添加Pythoe项目,按下图所示填写,启动命令python3 app.py,环境变量 无,启动用户 root,然后把安装依赖包勾上点击确定即可。 图片 等待项目部署完成,显示正在尝试启动项目,就可以关闭窗口,然后点击项目设置,选择项目日志扫码你的机器人即可(账号需实名,支付需可用,否则可能登录不上) 图片 Docker部署方案 以宝塔为例,安装Docker环境,按下图所示全部默认即可 图片 打开网盘资源管理网站的根目录,进入chatgpt-on-wechat文件夹 图片 打开config.json文件,修改duanju_url字段为你的网盘资源管理系统的网址,测试群聊改成你群聊名称保存,一行授权一个群聊 图片 在本目录打开终端并执行命令以下命令后回车,然后等待完成 sudo docker compose up -d 注意:由于国内可能无法访问到Docker源站,可能执行以下指令会无法完全安装完成,请下载chatgpt-on-wechat项目文件上传到本地镜像或添加国内镜像仓库即可解决! 图片 图片 图片 安装完成 图片 (图源来自 凡星爱分享博客) 最后按下图序号依次点击,扫码你的机器人即可(账号需实名,支付需可用,否则可能登录不上) 图片 大功告成 宝塔添加计划任务,按下图所示,删除用户全网搜后的资源 设置每隔30分钟监控一次即可 https://你的域名/api/other/delete_search 图片 图片 config.json配置说明 # config.json文件内容示例 { "model": "gpt-3.5-turbo", # 模型名称, 支持 gpt-3.5-turbo, gpt-4, gpt-4-turbo, wenxin, xunfei, glm-4, claude-3-haiku, moonshot "open_ai_api_key": "YOUR API KEY", # 如果使用openAI模型则填入上面创建的 OpenAI API KEY "open_ai_api_base": "https://api.openai.com/v1", # OpenAI接口代理地址 "proxy": "", # 代理客户端的ip和端口,国内环境开启代理的需要填写该项,如 "127.0.0.1:7890" "single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复 "single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人 "group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复 "group_name_white_list": ["机器人测试群", "机器人测试群2"], # 开启自动回复的群名称列表 "group_chat_in_one_session": ["机器人测试群"], # 支持会话上下文共享的群名称 "image_create_prefix": [], # 开启图片回复的前缀 "conversation_max_tokens": 1000, # 支持上下文记忆的最多字符数 "speech_recognition": false, # 是否开启语音识别 "group_speech_recognition": false, # 是否开启群组语音识别 "voice_reply_voice": false, # 是否使用语音回复语音 "group_welcome_msg": "", # 配置新人进群固定欢迎语,不配置则使用随机风格欢迎 } 个人聊天 个人聊天中,需要以 "bot"或"@bot" 为开头的内容触发机器人,对应配置项 single_chat_prefix (如果不需要以前缀触发可以填写 "single_chat_prefix": [""]) 机器人回复的内容会以 "[bot] " 作为前缀, 以区分真人,对应的配置项为 single_chat_reply_prefix (如果不需要前缀可以填写 "single_chat_reply_prefix": "") 群组聊天 群组聊天中,群名称需配置在 group_name_white_list 中才能开启群聊自动回复。如果想对所有群聊生效,可以直接填写 "group_name_white_list": ["ALL_GROUP"] 默认只要被人 @ 就会触发机器人自动回复;另外群聊天中只要检测到以 "@bot" 开头的内容,同样会自动回复(方便自己触发),这对应配置项 group_chat_prefix 可选配置: group_name_keyword_white_list配置项支持模糊匹配群名称,group_chat_keyword配置项则支持模糊匹配群消息内容,用法与上述两个配置项相同。(Contributed by evolay) group_chat_in_one_session:使群聊共享一个会话上下文,配置 ["ALL_GROUP"] 则作用于所有群聊 全网搜采集站更改地址 网盘程序根目录/app/common.php 第793行到结尾 警告:如转载文章,请注明出处以及链接,保留原作者劳动成果,谢谢!
-
夸克网盘空间不足?私人教程教你免费升级60T 注册开通 大家都知道目前文件储存和分享90%都是用网盘来工作的,比如百度,阿里,123这几个都是前两年经常用的,不过半年前时迁就开始用夸克和uc进行储存和分享了 一 .是空间大但是夸克有限速需要开通会员,会员连续开通一个月也才是个3快多点挺良心了我说实话我自己就直接开了一年 二 .是不限速的UC网盘,主打的就是一个“猴急就用UC”空间也算可以之前有活动可以免费领取1个T的空间会员和空间也可以通过UC页面进入活动免费抽奖 那么接下来我们讲一讲怎么去免费扩容这两个网盘的空间储存分享资源还能过去收益吧 两个平台: 一:夸推班(推荐) 去除繁琐的步骤,微信扫码注册就送26T和15天会员,已注册其他平台的有详细换平台教程 图片 二:任推帮 1.首先第一步点击下方链接进行注册,一定要从我这链接注册 https://dt.bd.cn/#/pages/login/register?invite_code=503703 2.注册好以后进入主页就可以看到很多任务我们直接先一步选择夸克网盘任务申请 图片 3.填写对应的信息这个我就不多说了,人家写的很清楚除了手机号和UID必须要填对,剩下的可以随意 图片 4.申请成功后就可以在夸克任务的页面点击我的推广码,即可查看 当然,这里也是有收益金额显示。至于我为什么这么做,因为我已经推广半年了,大家去申请下来之后推广自己网盘的链接,分享出去别人从你的链接转存东西就可以收益的哦 图片 5.最后一步便是申请扩容了,但是官方这边有给你显示就是说你的网盘使用率必须高达80%以上,也就是说你的网盘里必须要转出东西转存满之后才可以去进行申请。第一次是20t,第二次是40t,第三次是60t,UC也是同样的操作 如果你没有资源转存那么好我这里有直接去 dj.uos.cx 短剧网址转存就行,如果嫌慢那么好找我,20块给你一晚上存满 图片
-
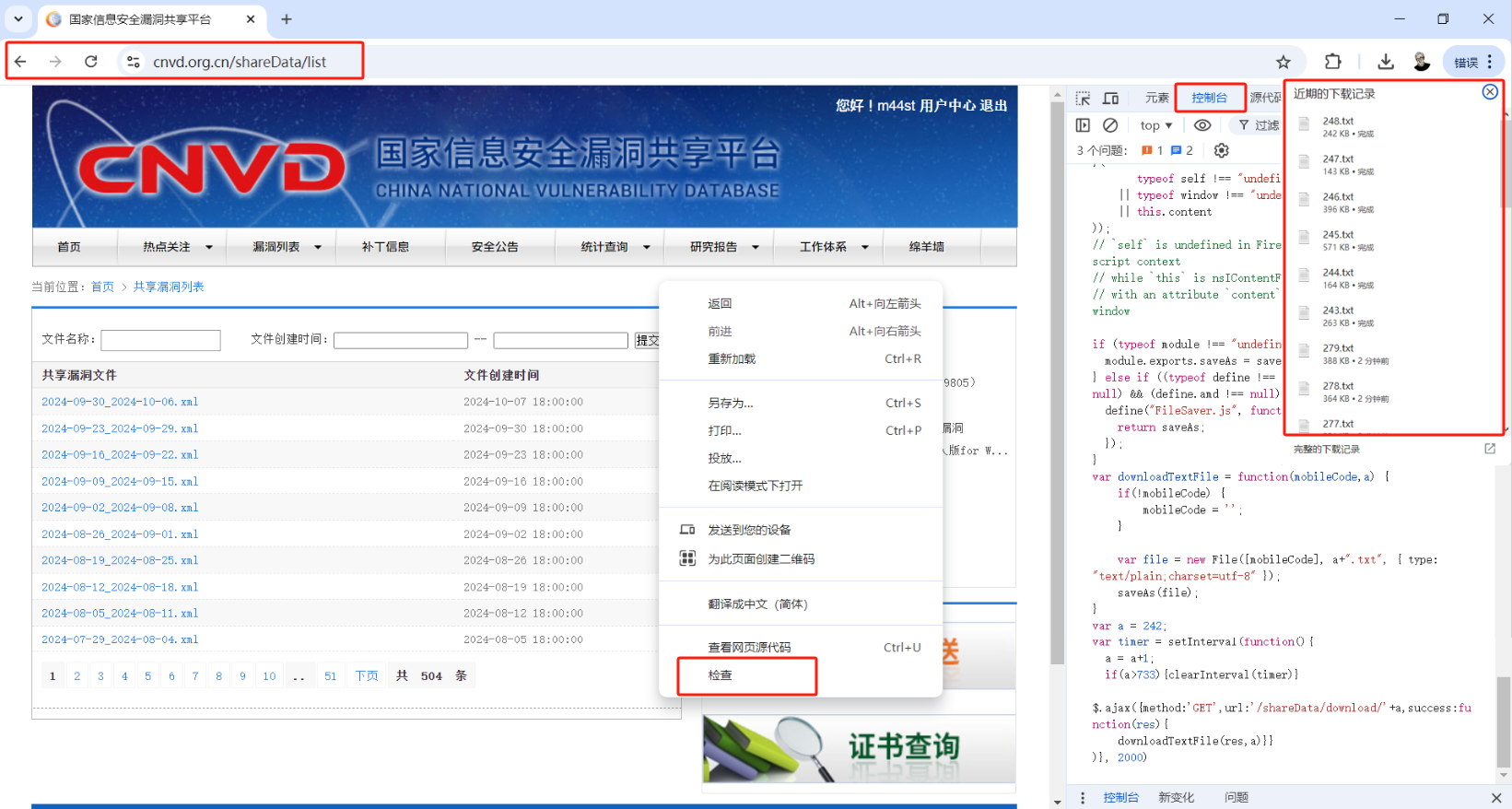
CNVD漏洞库数据采集详解 背景 在21世纪的信息安全领域,网络安全已经成为各个领域关注的焦点。随着全球网络攻击事件的增多,企业和个人面临的安全挑战也愈发严峻。掌握最新的漏洞信息是强有力的防御措施之一,而 CNVD(China National Vulnerability Database,即中国国家信息安全漏洞共享平台)作为中国的重要资源库,为研究人员和网络安全从业者提供了全面的漏洞数据支持。本指南将详细解析如何通过自动化脚本方案,稳妥、高效地获取 CNVD 提供的共享 XML 数据。 前期准备 账户注册与验证 在开启数据之旅之前,首要任务是注册并登录 CNVD 平台账户。使用以下步骤确保您获得全面访问权限: 访问官网 :打开浏览器,输入 [CNVD 官方网站]。 账户创建 :查找页面中的注册按钮,点击进入注册页面。注册过程可能需要填写详细的个人信息,包括用户名、电子邮箱、密码等。 邮箱验证 :提交注册信息后,您会收到一封来自 CNVD 的邮件,包含账户激活链接。请及时查阅您的邮箱并激活账户以完成注册流程。 注册并登录后,您可以访问共享数据下载页面。获得数据访问权限不仅是为了获取技术资料,也是为了合法合规地遵循平台使用条款。 浏览器环境配置 为确保脚本的流畅运行,我们推荐使用现代化的浏览器,如 Google Chrome 或 Mozilla Firefox。这些浏览器对 JavaScript 的支持完善,通过配合开发者工具,能够更好地进行脚本调试与执行。 安装插件 :确保浏览器支持 JavaScript 和相关功能扩展。必要时,您可以访问浏览器扩展商店下载开发者友好的插件,比如 JSON Viewer、XML Formatter 等工具。 启用开发者工具 :在浏览器中按下 F12 键(或通过菜单访问工具)可以开启开发者工具。在进行脚本开发及调试过程中,该工具是不可或缺的。 需求分析 数据的重要性与挑战 在复杂的网络环境中,漏洞信息的及时性和完整性是保障网络安全的基石。准确掌握潜在威胁,制定有效防御措施,不仅可防止经济损失,也可保护企业声誉。由于 CNVD 提供的漏洞信息详尽而及时,是开展漏洞研究与安全分析的重要数据源。 然而,直接的爬虫抓取方式常常因受反爬机制限制而面临挑战。因此,我们转而关注 CNVD 提供的共享数据接口,以低频、不干扰的访问策略实现数据的批量获取。 自动化解决方案 为实现数据的自动化下载,我们探讨如下两种方案: 按钮自动点击 :通过脚本模拟用户在页面上点击下载链接,通过设置浏览器的不同选项,实现自动翻页下载。这种方法需要处理页面DOM元素,难度较高。 链接请求循环 :通过发送请求获取每个独立数据链接,这是基于URL结构规律实现的爬虫方案。这一方法实现路径简单明了,只需了解页面的链接结构,即可实现自动化。 经过对比后,我们选择了第二种方案。经过页面分析,发现 CNVD 的数据下载链接遵循 https://www.cnvd.org.cn/shareData/download/ 编号 的模式,这为自动化提供了技术可行性。 实施步骤 图片 引入 FileSaver.js 由于浏览器环境的限制,JavaScript 默认无法直接保存文件。因此,我们引入 FileSaver.js 这一 JavaScript 库,允许在客户端环境保存文件。具体步骤如下: 脚本与引入 : 下载 并引入。 库初始化:在网页中,通过 <script> 标签加载库文件,确保在后续代码调用时已完成加载。 <script src="path/to/FileSaver.min.js"></script> 脚本开发与测试 var downloadTextFile = function(content, fileName) { if(!content) content = ''; // 确保内容非空 var file = new File([content], fileName + ".xml", { type: "application/xml;charset=utf-8" }); saveAs(file); }随后,通过 jQuery 实现 AJAX 请求,以遍历并获取所有数据链接: var start = 242; var end = 733; // 应根据 CNVD 实时更新调整 var timer = setInterval(function() { if (start > end) { clearInterval(timer); console.log('下载完成'); return; } $.ajax({ method: 'GET', url: '/shareData/download/' + start, success: function(res) { console.log('下载成功: ' + start); downloadTextFile(res, 'CNVD-' + start); start++; }, error: function(err) { console.log('下载失败: ' + start); start++; } }); }, 2000);说明:调试过程中,观察是否存在请求频率超出网站限制的情况,可适时调整setInterval的时间参数。 数据处理与清洗 完成下载后,需对文件进行数据清洗。可能会有一些文件因为内容为空而不需要保留。使用 Python 脚本,自动删除这些体积较小的文件: import os def clean_directory(path): for root, _, files in os.walk(path): for file in files: file_path = os.path.join(root, file) if os.path.getsize(file_path) < 2048: # 小于2KB的文件 os.remove(file_path) print(f"Removed: {file_path}") if __name__ == '__main__': download_path = './CNVD' clean_directory(download_path)总结与展望 完成上述步骤后,您将获得未经清洗与处理的漏洞 XML 文件。在数据的应用阶段,可以进一步结合数据分析手段、自然语言处理技术进行信息提取与漏洞特性挖掘。 在网络安全快速演变的背景下,持续的漏洞数据监测和分析将为机构提供坚实的安全基础。随着 CNVD 更新的持续和技术的革新,希望本指南能为网络安全从业者提供实用支持,并帮助大家在信息安全的道路上走得更远。 通过本次扩展,我们在详细讲解每个实施步骤的同时,还提供了重要的背景知识及操作细节,以帮助您充分利用 CNVD 数据进行安全研究。如果您有更具体的需求或问题,欢迎与我讨论与交流。